Accuracy assessment is a fundamental step after land cover classification in order to evaluate errors, globally and for each class, and finally evaluate the reliability of the map.
This post is a tutorial about accuracy assessment of a land cover classification using the Semi-Automatic Classification Plugin (SCP) for QGIS. We are going to use the function of SCP to create ROIs using stratified random points (a new function of SCP 6.4.0), which will be photo-interpreted and used as reference for the accuracy assessment. The SCP tool Accuracy will take care of the rest, providing the error matrix and the accuracy estimates.

This post is a tutorial about accuracy assessment of a land cover classification using the Semi-Automatic Classification Plugin (SCP) for QGIS. We are going to use the function of SCP to create ROIs using stratified random points (a new function of SCP 6.4.0), which will be photo-interpreted and used as reference for the accuracy assessment. The SCP tool Accuracy will take care of the rest, providing the error matrix and the accuracy estimates.
Accuracy assessment is performed comparing a sample of points (ground truth) to the classification. There are several ways to choose the sample size and the allocation thereof (sample scheme). The sample should be designed in order to achieve low standard errors of accuracy estimates, and usually this is achieved by random selection of samples.
Sample design depends on several variables such as the proportions of land cover classes and the standard errors that we expect for the overall land cover classification and single classes. In order to reduce standard errors of class specific estimates, it is recommended to stratify the sample. For further details about how to determine the sample size and the stratification, please refer to “Olofsson, et al., 2014. Good practices for estimating area and assessing accuracy of land change. Remote Sensing of Environment, 148, 42 – 57”.
1. Sample Design
This tutorial assumes that you have already performed the classification of a Landsat image following the instructions of this previous Tutorial 1: Your First Land Cover Classification. You can download the classification raster from this archive .
The land cover classes are described in the following table.
Classes
| Macroclass name | Class ID |
|---|---|
| Water | 1 |
| Built-up | 2 |
| Vegetation | 3 |
| Bare soil (low vegetation) | 4 |
Basically, the main requirement is to provide an adequate number of samples for each class, even if the class area proportion () is low. The number of samples () should be calculated as (Olofsson, et al., 2014):
N=(∑i=1 (Wi*Si)/So)2
where:
- Wi = mapped area proportion of class i;
- Si = standard deviation of stratum i;
- So = expected standard deviation of overall accuracy;
- c = total number of classes;
This requires some conjectures about overall accuracy and user’s accuracy of each class. We should base these conjectures on previous studies. One can hypothesize that user’s accuracy is lower and standard deviations Si is higher for classes having low area proportion, but of course these values should be carefully evaluated.
To get start QGIS and load the classification raster.
To get start QGIS and load the classification raster.
Open the SCP menu and click the tab
Postprocessing . This tool allows for estimating class area and class percentage.
Click the button

Classification report
The report table contains the percentage of each class, which we divide by 100 to get the required Wi. In this tutorial we assume So=0.01 and conjecture the Si values reported in the following table (of course, these assumptions are specific of this classification, other assumptions should be made for other classifications).
Conjectured standard deviations
| Land Cover Class | Area | |||
|---|---|---|---|---|
| 1 | 976,500 | 0.0033 | 0.4 | 0.0013 |
| 2 | 111,267,000 | 0.3713 | 0.3 | 0.1114 |
| 3 | 187,018,200 | 0.6240 | 0.2 | 0.1248 |
| 4 | 438,300 | 0.0015 | 0.5 | 0.0007 |
| Total | 0.2382 |
Therefore, is the number of samples that we should distribute among classes.
To stratify the sample we should conjecture user’s accuracy and standard deviations of strata (Olofsson, et al., 2014).
A rough approximation is considering the mean value between equal distribution (c ) and weighted distribution (), which is as illustrated in the following table.
Sample stratification
| Land Cover Class | Weighted | Equal | Mean |
|---|---|---|---|
| 1 | 2 | 142 | 72 |
| 2 | 210 | 142 | 176 |
| 3 | 354 | 142 | 248 |
| 4 | 1 | 142 | 71 |
| Total | 567 |
2. Sample Collection and Photo-Intepretation
This phase involves the creation of (randomly selected) single pixel Training Areas (ROIs), and the attribution of a land cover class based on photo-interpretation of each ROI.
First, we need to define a Band set containing the classification raster that is an input required by the other tools we are going to use.
Open the tab Band set clicking the button
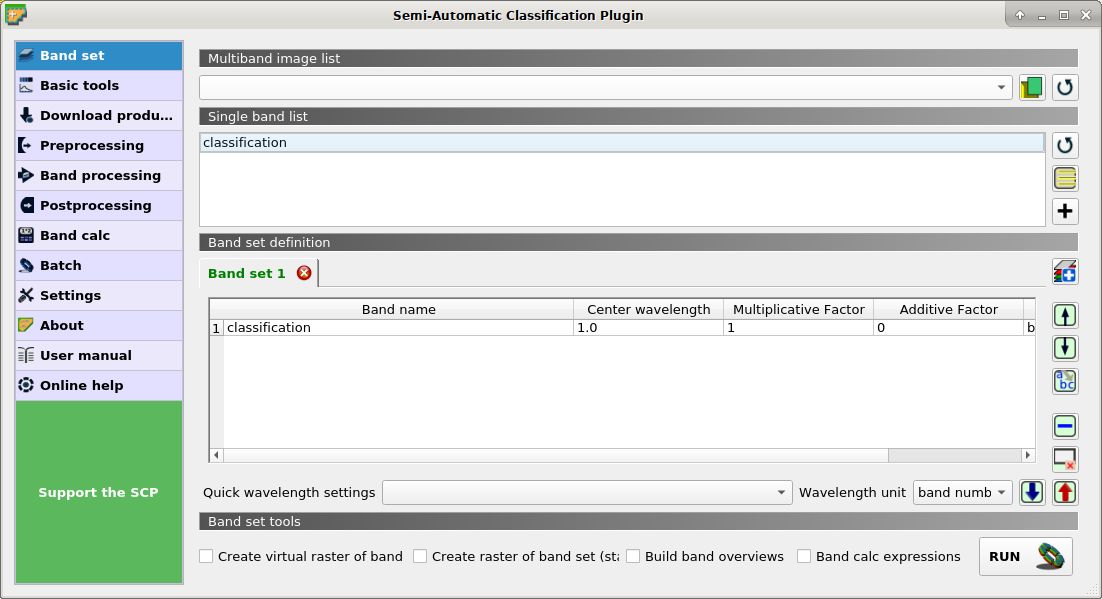 Band set definition
Band set definition
We need to create the Training input in order to collect ROIs that will be the actual samples.
In the SCP dock select the tab Training input and click the button

sample.scp). The path of the file is displayed and a vector is added to QGIS layers with the same name as the Training input (in order to prevent data loss, you should not edit this layer using QGIS functions).
Training input
Now we are going to create the stratified random sample using the SCP tool Multiple ROI creation. This tool allows for the random creation of point coordinates according to the sample scheme previously defined.
TIP : In case you have already collected samples you can import (using the button) a shapefile or a csv file containing the coordinates and the classification codes.
This tool works in two steps:
- randomly select point coordinates defining ROI parameters;
- actually create ROI polygons based on point coordinates;
During the first step, in addition to point coordinates, other fields are automatically filled in the table from the parameters set in the Working toolbar, such as the minimum and maximum ROI size. In this tutorial we use single pixel ROIs, although cluster sampling (several pixels per ROI) is also used for accuracy assessment. To avoid manually editing these fields after the random point creation, in Temporary ROI we need to set the parameters Min = 1 and Max = 1. Created random samples will have the size of 1 pixel.

Multiple ROI creation
To reduce the photo-intepretation time (considering the illustrative purpose of this tutorial and that the classification is a subset of a Landsat image), we are going to divide the number of samples by 10 according to the following table (of course, in real cases we must use all the samples as designed).
Number of stratified samples
| Land Cover Class | Samples |
|---|---|
| 1 | 7 |
| 2 | 18 |
| 3 | 25 |
| 4 | 7 |
| Total | 57 |
In Number of points enter 7 that is the number of samples designed for class 1. In the tab
raster == 1 (notice the double “=”). This expression means that we are going to randomly select points that fall over pixels having value 1 of the classification (that is the first band of the Band set 1).
Therefore click Create points

Samples for class 1
Now we repeat the above steps for class 2. In Number of points enter 18 and in stratified for the values enter
raster == 2. Click Create points
Repeat the same steps for class 3 (25 points and
raster == 3) and for class 4 (57 points and raster == 4). Now that we have all the required samples we can create the ROIs (the single pixel polygons that will be photo-interpreted).
Uncheck the option

Samples added to the training input
The type
R means that, of course, spectral signatures were not calculated. All the created ROIs have the same MC ID (i.e. macroclass ID) and C ID (i.e. class ID); now we can assign the correct class (MC ID) to each ROI with photo-interpretation using images with resolution higher than the classification, or other services such as OpenStreetMap).
In the ROI Signature list, double click on the first ROI in order to zoom to the ROI; after photo-interpreting the class we can assing the correct MC ID and C ID with a click on the corresponding field in the ROI list.

A sample over a road photo-interpreted using a Copernicus Sentinel-2 image
Of course we need to perform the photo-interpretation of all the samples, assigning the correct code. The photo-interpretation should be performed without considering the classification raster. It is worth highlighting that spatial resolution (i.e. 30m) implies mixed pixels (i.e. pixels made of multiple materials at ground); therefore, during the photo-interpretation we must consider the most prevalent land cover in the ROI area.
3. Calculation of Accuracy Statistics
After the photo-interpretation of all the samples, we can perform the accuracy assessment by comparing the ROIs to the classification. If you have skipped the previous step, you can download the photo-interpreted sample from here .
The process will produce an an error raster (a
.tif file showing the errors in the map, where pixel values represent the combinations between the classification and reference identified by the ErrorMatrixCode in the error matrix) and a text file (i.e. a .csv file separated by tab) containing the error matrix and the accuracy statistics.
In Select the classification to assess
classification (click the button
In Select the reference vector or raster
sample vector that is the Training input, and in Vector field MC_ID that is the vector field containing the class values.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The tool Accuracy
After the calculation the accuracy statistics are displayed in the output interface and the error raster is loaded in QGIS.

Output
Several statistics are calculated such as overall accuracy, user’s accuracy, producer’s accuracy, and Kappa hat. In particular, these statistics are calculated according to the area based error matrix (Olofsson, et al., 2014) where each element represents the estimated area proportion of each class. This allows for estimating the unbiased user’s accuracy and producer’s accuracy, the unbiased area of classes according to reference data, and the standard error of area estimates and the confidence intervals. Of course the standard errors are influenced by the low number of samples that we have collected in this tutorial.
Area based error matrix
| Reference | |||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||
| Classified | 1 | 0.0023 | 0 | 0.0009 | 0 |
| 2 | 0 | 0.3094 | 0.0619 | 0 | |
| 3 | 0 | 0.0998 | 0.5242 | 0 | |
| 4 | 0 | 0 | 0.0004 | 0.0010 | |
| Total | 0.0023 | 0.4092 | 0.5874 | 0.0010 | |
The overall accuracy is 83.7% that is a good result (above 80%). However, this classification was produced for the first basic tutorial, therefore the classification could be improved. Also, note that we used a number of samples lower than designed sample.
The user’s and producer’s accuracy are provided for each class.
Producer’s and user’s accuracy
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| Producer’s accuracy | 100.0 | 75.6 | 89.2 | 100.0 |
| User’s accuracy | 71.4 | 83.3 | 84.0 | 71.4 |
Unbiased area estimates
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| Area | 697,500 | 122,645,412 | 176,044,017 | 313,071 |
| 95% Confidence interval Area | 352,984 | 33,778,661 | 33,780,877 | 158,436 |
For any comment or question, join the Facebook group about the Semi-Automatic Classification Plugin.